Two years ago, our team at Lighthouse Reports set out to investigate the growing use of algorithmic risk assessments in European welfare systems. Trained on millions of sensitive data points from welfare recipients, these systems make life-changing decisions about some of the continent’s most marginalised communities.
It has been a challenging endeavour that has involved more than a hundred public records requests across eight European countries. In March of 2023, we published a four-part series co-produced with WIRED examining the deployment of algorithms in European welfare systems across four axes: people, technology, politics, and business. The centrepiece of the series was an in-depth audit of an AI fraud detection algorithm deployed in the Dutch city of Rotterdam.
Far-reaching access to the algorithm’s source code, machine learning model and training data enabled us to not only prove ethnic and gender discrimination, but also show readers how discrimination works within the black box. Months of community-level reporting revealed the grave consequences for some of the groups disproportionately flagged as fraudsters by the system.
We have published a detailed technical methodology explaining how exactly we tested Rotterdam’s algorithm with the materials we had. Here, we will explain how we developed a hypothesis and how we used public records laws to obtain the technical materials necessary to test it. And, we will share some of the challenges we faced and how we overcame them.

As a nonprofit journalism organization, we depend on your support to fund more than 170 reporting projects every year on critical global and local issues. Donate any amount today to become a Pulitzer Center Champion and receive exclusive benefits!
How It Began
When we began this project, we did so with the conviction that journalism had a role to play in interrogating algorithms that make life-changing decisions about vulnerable populations. One of the most pernicious examples of this within Europe is in welfare systems, where politicians promise to recover millions of allegedly lost euros with the help of opaque algorithms.
The pitch for these systems from governments and private vendors was clear. They claimed that they were objective, fair and efficient. In a white paper about the algorithm in Rotterdam, Accenture, the city’s technology partner, wrote in large block letters that using fraud prediction technology would result in “unbiased citizen outcomes.” And, in an interview with Dutch public broadcaster VPRO, Rotterdam alderman Richard Moti said that there was “no bias in both the input and output” of the city’s algorithm.
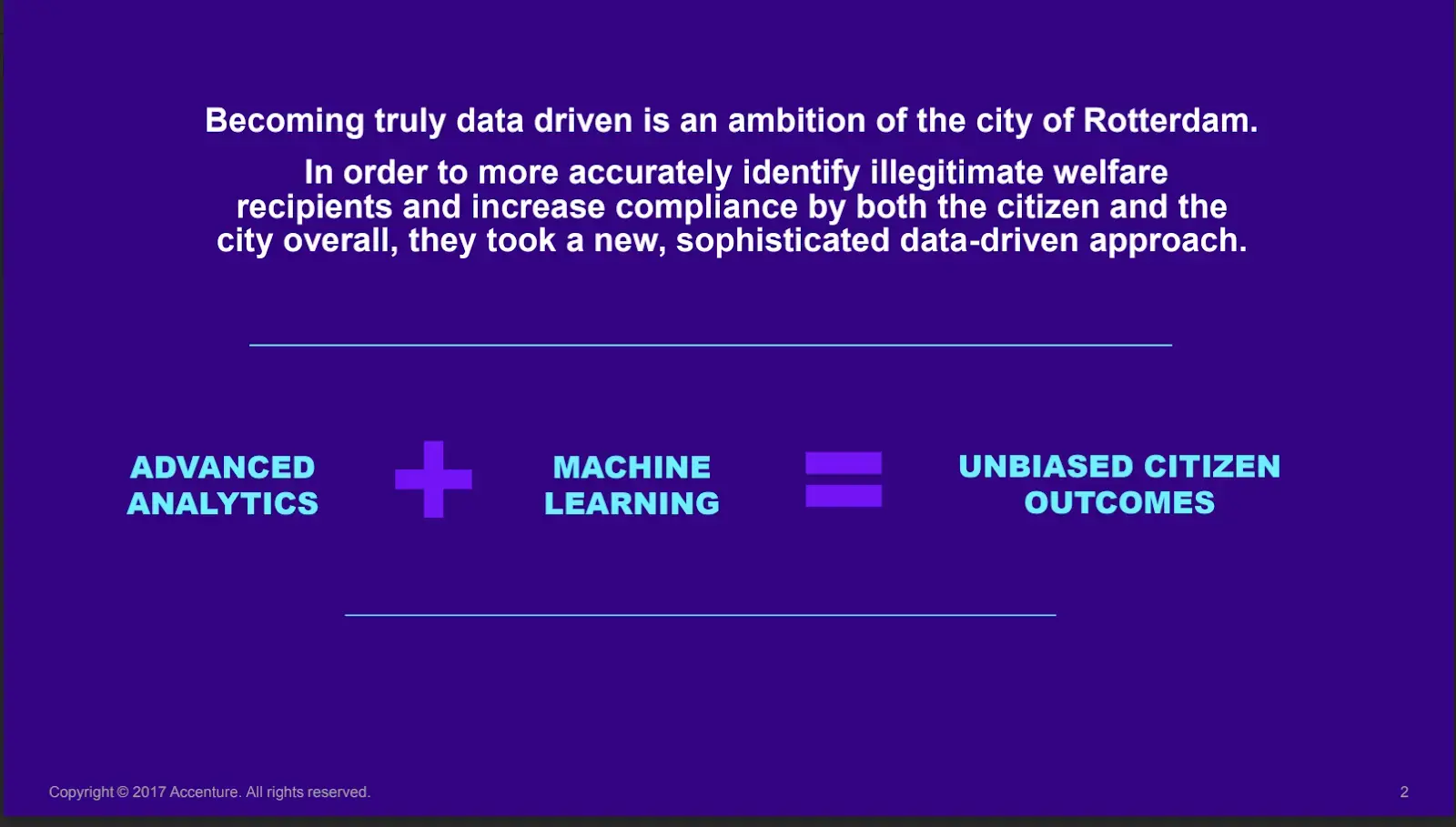
Accenture did us a favour by providing us with very clear claims to test. But in order to test them, we knew we would both have to obtain high levels of technical access and to go on-the-ground to see the effects of this technology on impacted communities.
FOIA-ing for Suspicion Machines
The difficulty in obtaining access to algorithms under public records laws has meant that much of algorithmic accountability up until now has focused on outputs. ProPublica’s Machine Bias, a flagship investigation in this space, examined how predictions from risk assessment software deployed in the US criminal justice system was biased against African Americans.
One of the goals of our reporting was to audit the full lifecycle of an algorithm. In practice, this means looking at the input variables (characteristics like age or gender) the algorithm uses, the data it’s trained on, the type of machine learning model (in this case, a system based on hundreds of decision trees) and whether its outputs disproportionately target certain groups.
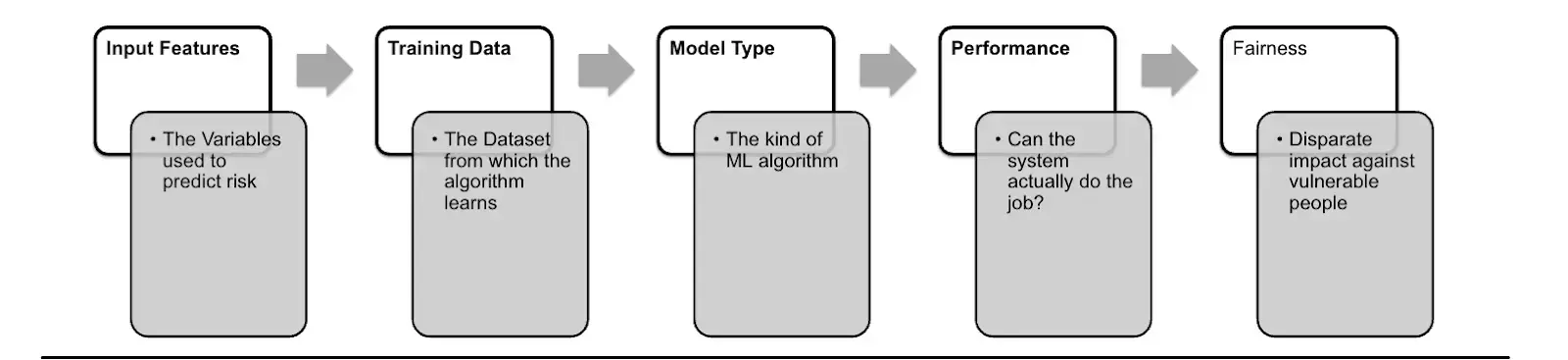
We designed a public records request that covered the different components of this lifecycle. You can find our exact template here and a breakdown of each component in the table below. For those looking to use public records laws in a cross border project, I strongly suggest checking out the website of Access Info Europe and specifically its Right To Information rating. In the United States, I found this extensive thread from the Benefits Tech Advocacy Hub on strategies for requesting algorithms through FOI to be quite helpful.
| FOI Toolkit for Algorithms | |||
| Item | Difficulty | Questions you can ask: | Examples of what we received |
| Training data | Very hard | Is the training dataset representative? What sampling procedure was used? | synth_data.csv* This is synthetic data, not the real training data. |
| Machine learning model | Hard | Is everybody judged according to the same criteria? Which groups are getting higher scores? Which groups are misjudged more frequently? | finale_model.rds Can be imported into RStudio. |
| Source code | Hard | What intentional design choices have the developers made and how do they affect the system? Are variables automatically chosen or are they hard-coded into the system? | model_brondcode |
| Input Variables | Medium | Are protected categories used? Are there obvious proxies? | Rotterdam variable list.pdf |
| Performance evaluations | Medium | How good is the system at doing its job? What criteria are being used to evaluate performance? Do they make sense in the context of the system? | Model performance evaluations.html |
| Technical documentation | Medium | Rotterdam handbook for data scientists.pdf | |
| Caseworker handbooks | Easy | How much knowledge do caseworkers have of how the system works? How are caseworker decisions fed back into the system? | Social worker scoring guidelines.pdf |
| Data or Privacy Impact Assessments | Easy | Is the system using any potentially problematic categories of data? What risks does the agency acknowledge? Has it done anything to mitigate those risks? | Privacy impact assessment Rotterdam.pdf |
We did not always ask for all of these pieces all at once. Typically, we started with a series of questions to an agency’s press department about the agency’s use of AI. Questions included whether it used machine learning for fraud prediction, the name of any fraud prediction systems, and the general categories of data it used. We did this for two reasons: First, to understand whether the agency was using a simple algorithm, or a more advanced machine learning algorithm. And second, to get a sense of how cooperative the agency would be.
If it was clear that an agency likely was not going to be cooperative, we would break our template request into smaller chunks. In our experience, uncooperative agencies would quickly shut down any line of communication once they understood that we were looking to audit their systems. So, instead of immediately asking for code or data, we would only ask for technical documents. Agencies that do not want to release documents are more likely to attempt to hold up your public records request for procedural reasons, such as an overly broad request. By FOIA-ing in parts, it is easier to make subsequent FOIs more precise. It also increases the chances that you will have documents to fall back on for your story, even if you are refused code.
The responses we received from different European countries were piecemeal. Sometimes we received technical documentation but no code, other times we received code but no documentation. From the beginning, Rotterdam was the most transparent. The city disclosed its source code and technical documentation. But when we began searching through the code, we noticed a crucial file was missing: the machine learning model, or the file that can actually calculate risk scores. Without that file, we could not understand how different groups were scored by the model nor how variables like gender influenced scores.
Obtaining the machine learning model file would be at the center of a yearlong battle with Rotterdam. The city, along with all the other countries we FOI’d, relied on exemptions within European FOI law that allows public bodies to refuse disclosing documents if the disclosure would hinder their ability to control for a crime or administrative offence. In other words, they argued that if the model file was disclosed, potential fraudsters would be able to game the system.
For the algorithms we have investigated, this argument is completely baseless. In legal arguments with Rotterdam, we pointed out that most of the characteristics used by Rotterdam’s algorithm are immutable, or nearly immutable, demographic characteristics. Changing one’s legal age, the most influential variable in the Rotterdam model, is nearly impossible. There is a robust set of academic literature on the so-called ‘gaming argument’ that we found useful to cite in our arguments.
Throughout our appeal process with Rotterdam, we had a series of sideline negotiations with city officials. A number of solutions were discussed, but every time agreement seemed on the horizon, the city backed out at the last second. At one point, the city agreed to create ‘synthetic’ training data that we could use to train a model similar, but not exactly the same, as the one used by the city. At another point, the city agreed to allow us into their ‘basement,’ where we could run tests on the real training data on an air-gapped machine and collect aggregate results. The meetings we did manage to arrange were accompanied by large periods of radio silence. During these lapses in communication, we pestered them with new FOIA requests and received a small, but steady drip of new documents. The idea was to give the message that we would not be letting this go.
In September of 2022 we attended an appeal hearing with an independent committee that would decide whether the city had to hand over the model file. It was clearly uncharted waters in Dutch public records law. At one point in our hearing, the chairwoman asked if the city could send her the machine learning model file as a PDF.
Days after the hearing, Rotterdam invited us for a meeting in the city hall. The city finally agreed to hand over the model file. We strongly believe that if we had not been negotiating with the city outside of the FOI procedure, we would have never been able to obtain the model file.
With the model file, we had the essentials necessary to run our experiment. But a stroke of luck landed us with the training data as well. When the city sent us a file containing statistical distributions for each of the algorithm’s variables, they inadvertently leaked the entire training dataset in the code. While not essential to running the experiment, the training data did enable the experiment to be more robust.
Human Interest Stories
Just as difficult as obtaining the technical materials to run our experiment was finding human stories to show why it mattered. We spent months trying to find people who would be willing to share their stories of the consequences of being flagged for fraud investigations. People were understandably afraid to speak. Many of them had suffered enormous consequences — like having their benefits temporarily stopped — at the hands of the city’s punitive welfare system. They felt pursued by the city, constantly in the crosshairs.
Working with Rotterdam metro Vers Beton, we visited community centers and lawyers specialised in welfare cases, and trawled Facebook groups where people receiving welfare shared their experiences with the system.
In the case of our story, the technical data work and ground reporting had a symbiotic relationship. While it was relatively simple to test how individual variables contributed to risk scores, the algorithm scored each combination of variables differently. With a nearly infinite combination of variables to test, ground reporting helped to inform ‘archetypes’ — collections of variables — to see how the system scored different profiles. Meanwhile, the results of our experiment with the system allowed us to identify which groups had the highest chance of being flagged by the algorithm and focus our search for affected people.
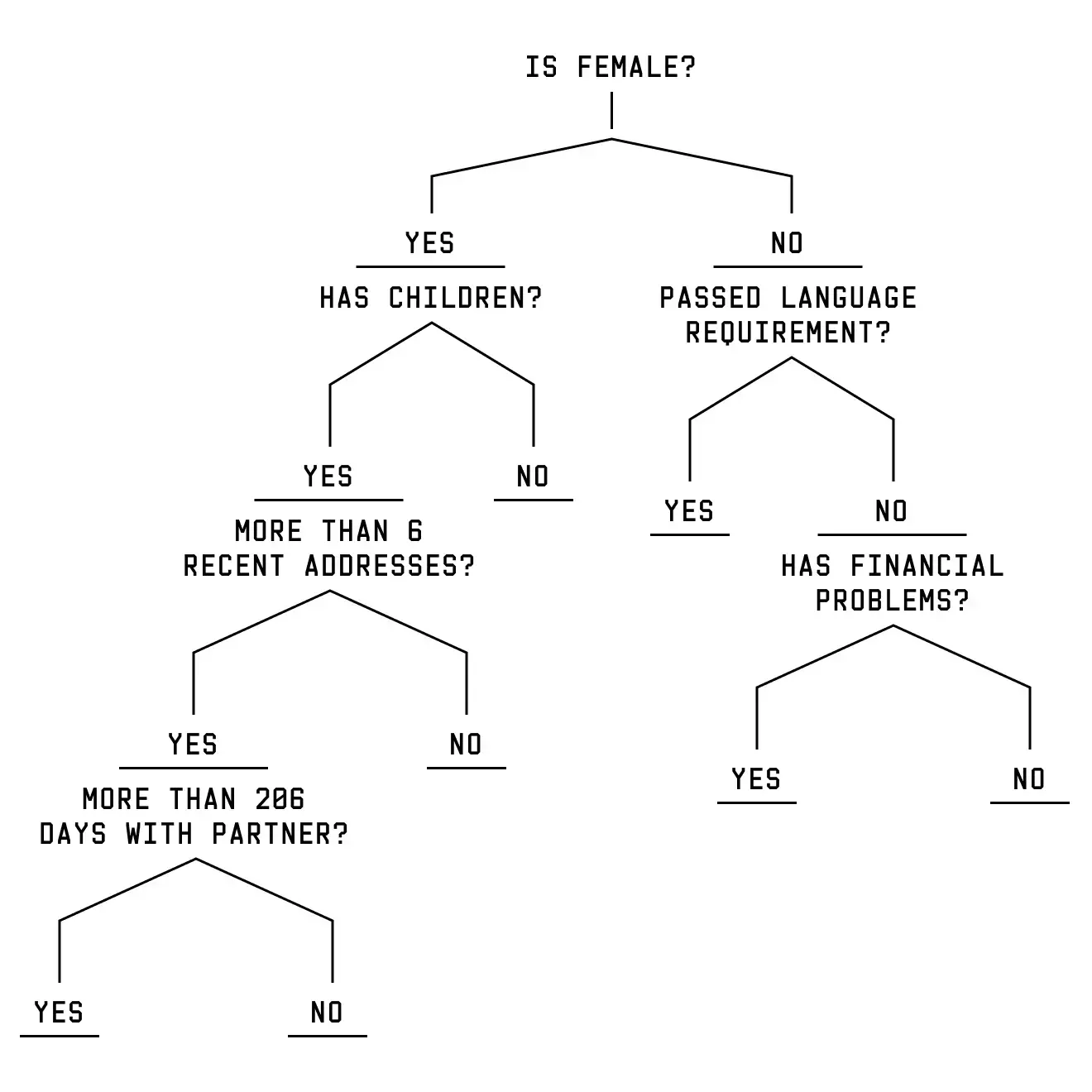
Our experiment established that single mothers of a migration background were one of the profiles assigned especially high scores by the system. Three reporters from Lighthouse and Vers Beton spent weeks sitting in on various informal mother’s groups across the city, where mothers have built their own support networks in the face of Rotterdam’s punitive social services. There are no shortcuts here to gaining trust.
One of the challenges was determining whether someone put under investigation was selected by an algorithm or by another means. We asked welfare recipients to send requests under Europe’s General Data Protection Regulation (GDPR) to access their risk score and the variables that had been used to calculate it. GDPR can be a powerful tool to use in situations where an authority is otherwise unwilling to share data. In the case of Rotterdam, the responses welfare recipients received also gave a disturbing look into how their complex lives had been flattened by the system and rendered suspicious. In the case of Oran, whose story we explore in one of the WIRED stories, even his mental health struggles were flattened into a variable that contributed to his risk score.
Bulletproofing the Story
The level of access we obtained and the complexity of Rotterdam’s machine learning model were uncharted territory for our team. The risk of error was high. Inspired by The Markup and The Marshall Project, we decided at an early stage that we were going to write a detailed methodology to accompany our story.
We convened a group of academics that included computer scientists, statisticians, and human rights experts who generously reviewed our methodology both before and after running our experiment. Internally, we footnoted every claim and number in our methodology and story with relevant results from our experiment. Dhruv Mehrota, an investigative data reporter at our partner WIRED and one of the authors of PredPol, played an integral role in red teaming the methodology.
Typically reporters only give the subjects of their investigations days or even hours to respond, but after sending Rotterdam our methodology and results we felt it was necessary to give the city three weeks. When Rotterdam did respond, they described the results of our investigation as “pertinent, instructive and partly recognizable” and said that it is “very important that other governments and organizations are aware of the risks of using algorithms.”
Finally, we published all of the materials and results from our experiment on Github, so people could check our work and test their own hypothesis with the Rotterdam model.
Takeaways
This type of reporting is hard, but it does not have to be impossible. At the beginning, we lost months of time by using poorly phrased FOIs and by being slow to realize what types of stories we could tell from the material we received in different focus countries. We hope that more newsrooms will take on this type of reporting and learn from some of our mistakes.

- One of the misconceptions of algorithmic accountability reporting is that it is only for newsrooms with AI or machine learning experts. What we actually needed was a small, multidisciplinary team of data reporters and community-level reporters.
- Our project required a large amount of time and resources. But it was also a huge exercise in trial and error spread across eight different countries. Begin your investigation with a well thought out FOI strategy and a sense of the stories you want to tell.
- Reporting these stories is already difficult, so collaborate. We wished we had brought in newsrooms in our respective focus countries at an earlier stage. In the case of Rotterdam, we needed strong beat reporters and editors from WIRED — along with its excellent design team — to turn a complex body of reporting into a compelling story. And we needed Vers Beton and its reporters with strong community connections and context knowledge to find and tell stories to and from the community that we were reporting on.
- We want more newsrooms to take on algorithmic auditing, but that does not mean you need it to tell powerful algorithmic accountability stories. Explaining a complex algorithm can consume oxygen that could otherwise be spent on exploring other angles. We had less technical access in our reporting on algorithms used by Spain’s social services, for example, but went deep into the stories of the caseworkers who used those algorithms in their everyday lives.
- Do not lose sight of the people and communities at the center of your story. In most cases, building community trust and telling human stories will be just as challenging as accessing and testing an algorithm.